I - Résumé
Les changements climatiques amplifient l’intensité et la fréquence des événements extrêmes tels que les tempêtes, les inondations, les sécheresses et les incendies de forêts. Cette évolution rend la gestion des risques de catastrophes et la réponse aux urgences plus complexes et critiques.
Dans ce contexte, il devient crucial de développer des outils avancés pour la détection rapide et précise des dommages causés par ces catastrophes. Les images satellites jouent un rôle clé dans cette démarche, car elles offrent une vue d’ensemble des zones sinistrées et permettent une surveillance continue des impacts.
Les avancées en apprentissage automatique et en vision par ordinateur, comme les réseaux de neurones convolutifs (CNN) et les architectures de réseaux de neurones spécifiques pour la segmentation d’images, permettent de détecter et d’analyser les dommages avec une précision accrue.
Grâce à l’entraînement d’architectures sur des données open source, il a été possible de faire de la transférabilité sur des images privées présentant des caractéristiques techniques différentes, telles que celles de la constellation Pléiades. À l’aide de plusieurs techniques de pré-traitement, il a été possible de faire de la détection de changement sur des images Pléiades de Kahramanmaraş, en Turquie, dans le cadre de l’activation de la Charte internationale Espace et catastrophes majeures, en utilisant un réseau de segmentation binaire et un réseau de segmentation multiclasse. En termes de performance, les réseaux de segmentation multiclasse, offrent une analyse plus détaillée et nuancée des dégâts par rapport aux réseaux de segmentation binaire.
Cependant, la plupart des images satellites obtenues dans le cadre de la Charte, présentent des angles de vue obliques et des conditions météorologiques défavorables, ce qui complique la tâche de détection de changements. Néanmoins, même dans ces conditions difficiles, il est possible d’identifier les bâtiments intacts, offrant des informations essentielles pour la gestion post-catastrophe.
II - Présentation générale
II.1 - Présentation du service EOLAB au CNES
a) L’observation de la Terre depuis l’espace
La télédétection regroupe l’ensemble des techniques et méthodes permettant l’analyse à distance des propriétés des objets grâce au rayonnement qu’ils émettent ou réfléchissent. Bien que la première photographie de la Terre remonte à 1858, c’est la révolution numérique, survenue plus d’un siècle plus tard, qui a véritablement permis l’acquisition d’images de la Terre depuis l’espace. En 1977, le programme SPOT a été lancé, devenant le premier programme européen d’observation de la Terre. Entre 1986 et 2002, il a fourni des images avec des résolutions allant de 10 mètres (SPOT-1) à 2,5 mètres (SPOT-5). Contrairement aux satellites américains LANDSAT, lancés dès 1972, les satellites SPOT étaient équipés de miroirs mobiles permettant la stéréoscopie.
Même si le CNES a clôturé le programme SPOT, cette série de satellites a jeté les bases de la
constellation de satellites Pléiades. Ces derniers sont agiles (le satellite peut modifier son orientation
pour prendre des images sans avoir à suivre une orbite stricte) et capables d’acquisitions d’images
stéréoscopiques, offrent une résolution atteignant 70 cm. Comme les satellites SPOT, les satellites
Pléiades ont une orbite héliosynchrone, ce qui signifie que leur plan orbital maintient un angle
constant par rapport à la direction du soleil. Cela permet au satellite de survoler un point précis
de la surface de la Terre à la même heure locale, garantissant des conditions d’éclairement similaires
pour des images prises à des jours différents à la même période de l’année.
b) Présentation du service EOLAB
D’avril à fin septembre 2024, j’ai effectué mon stage de fin de master au sein du service EOLAB (Earth Observatory Laboratory), service faisant partie de la direction technique et numérique (DTN). Créé en 2018 au sein de la sous-direction CD (Campus de la donnée) de la DTN du CNES, le service EOLAB a pour but de valoriser les données et algorithmes issus du spatial pour des utilisateurs finaux tels que des collectivités ou institutions, des organismes de défense ou des entreprises privées, allant de la startup au grand groupe. Via ce service gratuit, les chercheurs d’EOLAB vont si besoin jusqu’à effectuer des preuves de concept pour démontrer la faisabilité technique de la solution envisagée. Ce service permet également de préparer les données futures qui seront collectées par les prochains satellites.
Le programme rassemble une vingtaine d’experts techniques sur un vaste ensemble de thématiques de l’Observation de la Terre, avec une connaissance allant de la physique de la mesure
jusqu’aux algorithmes de traitement. Ainsi, ces scientifiques sont impliqués dans des thématiques
diverses telles que l’agriculture, la forêt, le climat et l’environnement, l’eau (hydrologie continentale, côtière, littorale ou maritime), les risques et les catastrophes naturelles, la santé, l’urbanisme
ou l’aménagement du territoire... Ce laboratoire pluridisciplinaire cherche notamment à favoriser
l’utilisation de l’Intelligence Artificielle (IA) et de la télédétection dans les entreprises françaises.

Figure 1 - Logo du service EOLAB appartenant à la DTN/CD au CNES. Crédits : EOLAB [4]
c) La Charte internationale Espace et catastrophes majeures
Le CNES est l’un des membres fondateurs de la Charte internationale Espace et catastrophes majeures, établie en 1999. Cette initiative collaborative réunit 17 agences spatiales qui fournissent des données satellitaires gratuites et accessibles à l’occasion de catastrophes naturelles. Les données incluent des images optiques, radar et infrarouges, selon la disponibilité des satellites et les conditions météorologiques. Les images satellitaires peuvent aider à évaluer les dommages, identifier les zones les plus touchées, coordonner les secours, surveiller l’évolution de la situation (notamment dans les incendies et les inondations) et faciliter la planification de la reconstruction (réhabilitation et reconstruction post-catastrophe).
Depuis le 20 octobre 2000, il y a eu plus de 890 activations de la charte dans 136 pays (voir Figure 2). Actuellement, près de 60 satellites sont opérationnels 24/7 dans ce cadre. Le CNES est souvent sollicité pour l’acquisition d’images lors d’activation de la Charte, car il peut mettre à disposition des images SPOT ou encore Pléiades, qui sont des satellites THR (très haute résolution). Il fournit aussi le traitement des données, la distribution rapide aux autorités locales et contribue au développement de nouvelles technologies et méthodologies pour améliorer la télédétection et l’analyse des données.
Néanmoins, il y a plusieurs difficultés dans l’acquisition des images rendant l’extraction d’informations complexe : les conditions météorologiques, le timing et la réactivité, la résolution, l’angle de la prise de vue, la coordination des agences, la technique des outils de traitement de données... Souvent les membres qui sont chargés de localiser les zones les plus touchées (tâche aussi appelée labellisation ou étiquetage) font ce travail manuellement, ce qui représente une tâche chronophage, coûteuse et complexe. Le groupe EOLAB se propose alors d’aider ces organismes, notamment le SERTIT (Service Régional de Traitement d’Image et de Télédétection) basé à Strasbourg, en développant des outils de détection automatique.

Figure 2 - Infographie officielle de la Charte internationale Espace et catastrophes majeurs regroupant les principaux chiffres liés à son activation ainsi que les organismes membres. Crédits : xView2 [14]
II.2 - Présentation du stage
Afin de valider mon master TSI (Techniques Spatiales et Instrumentation) suivi à l’Université Toulouse Paul Sabatier, d’avril à septembre 2024, j’ai réalisé un stage de validation au sein du groupe EOLAB du CNES. Au début de mon stage, plusieurs pistes de développement m’ont été proposées pour la détection de changement sur des images Pléiades de catastrophes naturelles, et j’ai choisi de me concentrer sur celles capturées dans des conditions dégradées.
En effet comme mentionné dans la Section II.1.c, les images, souvent acquises en urgence, sont parfois dégradées (satellites pas en position optimale, mauvaises conditions météorologiques, angle d’incidence élevé...). Ainsi, pour réaliser une cartographie rapide des dégâts causés par une catastrophe naturelle, il est nécessaire de développer des outils capables d’effectuer une détection automatique des changements dans ces conditions difficiles. Actuellement, la détection optique des changements est réalisée manuellement. L’objectif est donc de soutenir les annotateurs dans les tâches de labellisation, longues et coûteuses.
Un des outils qui permet de caractériser le plus rapidement et de manière automatique les changements et les dégâts liés aux catastrophes est l’utilisation de réseaux de neurones. Je me suis donc engagé à comprendre, concevoir et adapter des architectures de réseaux de neurones à partir d’un jeu de données pour détecter les bâtiments intacts, endommagés ou détruits dans des images Pléiades, obtenues après une catastrophe naturelle.
L’objectif est donc de pouvoir aider les différents membres de la Charte à automatiser le processus de labellisation et d’obtenir le maximum d’informations sur la région touchée par la catastrophe naturelle, même lorsque l’image semble difficile à exploiter.
Ainsi, dans un premier temps, je me suis orienté vers la reconnaissance des bâtiments intacts uniquement, afin de m’assurer que la méthode d’entraînement d’images de catastrophes naturelles par deep learning pouvait être une piste envisageable pour faire de la détection de changements. Je me suis basé sur l’entraînement par segmentation sémantique binaire à l’aide de masques associés aux images, grâce à des données open source. L’un des enjeux majeur de la détection de changement pour les images de la Charte est la transférabilité des modèles. En effet, dans le cas d’acquisition en urgence, ce n’est pas toujours le même satellite qui prend l’image (Pléiades, Worlview-3, etc.) et il faut donc mettre en place une méthode robuste qui peut fonctionner sur une grande diversité de capteur. En utilisant deux images, une avant et une après un événement, il est possible d’appliquer ce réseau de neurones entraîné pour détecter les changements optiques et localiser les bâtiments détruits dans l’image. Pour améliorer les prédictions, j’ai adapté une architecture de réseau de neurones afin qu’il apprenne à détecter directement les bâtiments endommagés et détruits, à l’aide de la segmentation sémantique multiclasse.
Constatant l’efficacité de ces méthodes pour détecter les changements dans des images Pléiades, j’ai décidé d’explorer la possibilité d’améliorer la détection des bâtiments dans les images dépointées ou prises dans de mauvaises conditions. Les résultats démontrent qu’il est possible de recueillir des informations précieuses même lorsque les conditions de prise de vue de l’image ne sont pas optimales.
III - Contexte scientifique
III.1 - L’imagerie spatiale appliquée aux catastrophes naturelles
a) L’observation de la Terre par imagerie spatiale
Dans l’imagerie spatiale, il y a deux types d’acquisitions d’images d’observation de la Terre à partir de satellites par :
- Optique passive : Cette méthode capte le rayonnement que la Terre émet et réfléchit. Cela inclut des mesures de l’albédo (réflexion de la lumière solaire) et du rayonnement direct du Soleil (voir illustration à gauche de la Figure 3). Elle permet de réaliser des images à haute résolution qui révèlent des détails fins de la surface terrestre.
- Radar actif : Contrairement à l’imagerie optique, le radar actif utilise des signaux émis par le satellite qui se réfléchissent sur la surface terrestre. Ce type de mesure est indépendant des conditions d’éclairage et météorologiques, ce qui en fait un outil précieux pour obtenir des images en conditions difficiles (voir illustration à droite de la Figure 3).
Les images de télédétection fournissent des données physiques précieuses telles que la luminance
et l’altitude, permettant ainsi de déterminer des coordonnées géographiques précises pour chaque
pixel. Nous allons nous intéresser uniquement aux capteurs TDI (Time Delay Integration) de type
push-broom (voir Annexe A), car c’est ce qui est utilisé pour la mission Pléiades. Ce choix de
capteur permet l’acquisition d’images satellites de haute résolution avec un meilleur rapport signal
à bruit mais nécessite un pilotage très fin pour éviter les éventuelles micro-vibrations.
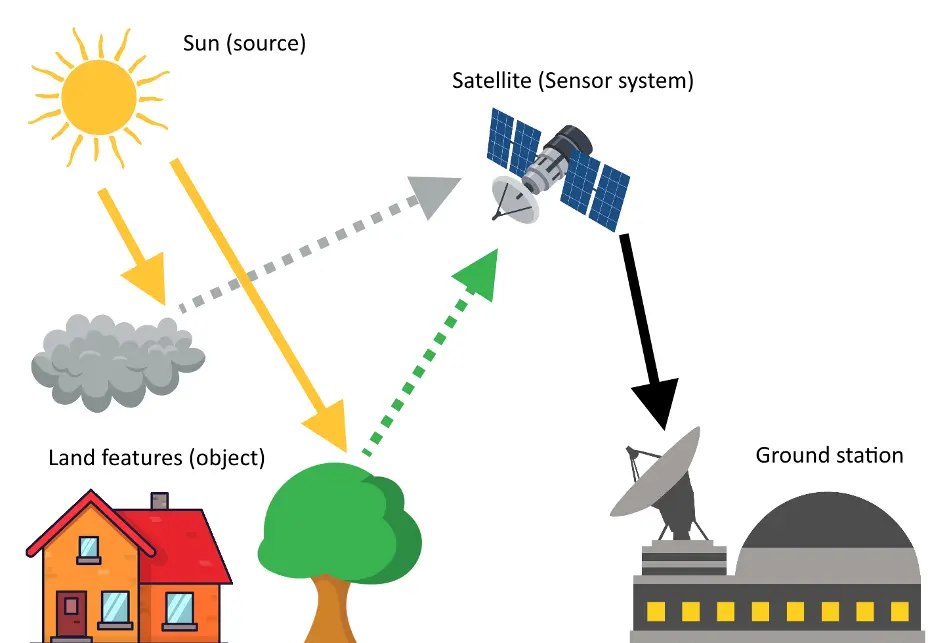
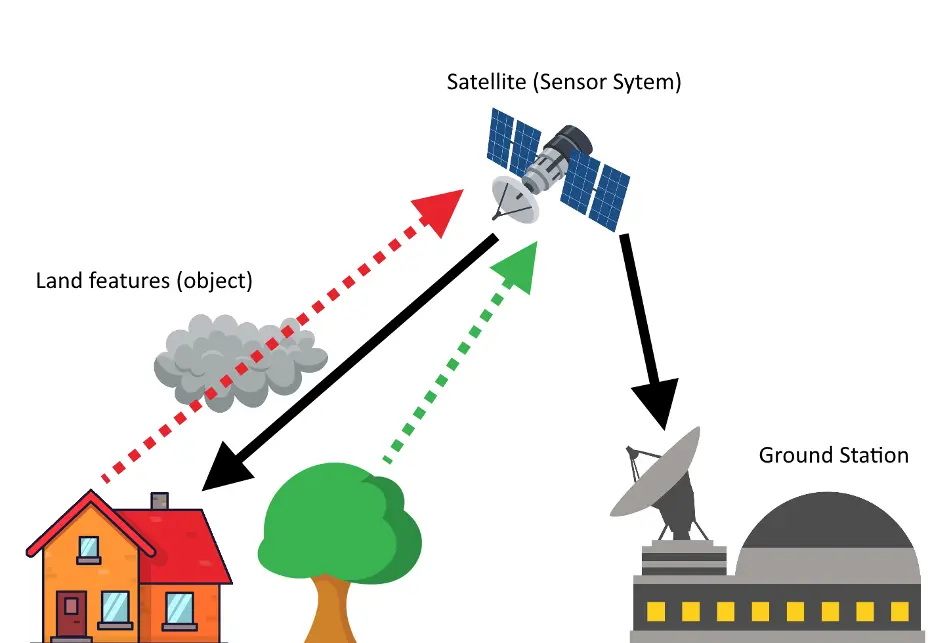
Figure 3 – Illustrations montrant le fonctionnement d’un satellite possédant un capteur d’optique passive à gauche et un capteur de radar actif à droite. Les ondes radar traversent la couverture nuageuse éventuelle, à l’inverse des ondes lumineuses dans le visible.
b) Suivi des catastrophes naturelles
Nous avons vu précédemment que l’imagerie spatiale permet d’établir des cartes en deux dimensions à grande échelle de n’importe quel endroit sur Terre. Une des applications d’observation de la Terre est le suivi des catastrophes naturelles par comparaison d’images avant et après la catastrophe. L’objectif est d’identifier le plus rapidement possible les zones touchées, les voies de circulation intactes ou les zones de déploiement possible des secours.
Lorsqu’une catastrophe naturelle majeure est signalée, les membres de la Charte (voir Section II.1.c) s’engagent à fournir des images et des cartes des dégâts aux autorités de sécurité civile dans les plus brefs délais. Les systèmes d’observation par satellite sont ainsi utilisés depuis quelques années que ce soit pour les tremblements de Terre (Kahramanmaraş en Turquie en février 2023), les éruptions volcaniques (Mount Ruang en Indonésie en avril 2024), les inondations (Lybie en septembre 2023), les cyclones et ouragans (Ouragan Fiona au Canada en septembre 2022) les feux de forêts (Argentine en août 2020), ou encore les pollutions maritimes (Marée noire à l’île Maurice en juillet 2020).
A la fin de la crise, les images satellites peuvent être à nouveau utilisées pour aider à quantifier les dégâts ou alimenter des bases de données d’entraînements de réseaux de neurones.
III.2 - Le réseau de satellites Pléiades
Le réseau de satellites Pléiades est constitué de deux satellites, Pléiades 1A et Pléiades 1B identiques. Ils ont été lancés respectivement le 17 décembre 2011 et le 2 décembre 2012 depuis le Centre spatial guyannais (CSG). Ce réseau a été initié et intégralement pris en charge par le CNES (Centre national d’études spatiales) et AIRBUS DS Geo. Le principal objectif de cette mission est d’avoir une cartographie fine des zones urbaines sur une fauchée de 20 km. Les satellites se situent à une altitude de 698 km sur une orbite LEO (Low Earth Orbit) héliosynchrone, avec une revisite quotidienne. Les satellites Pléiades sont dotés d’une grande agilité, leur permettant de changer rapidement d’angle de visée. Ces qualités permettent la capture d’images de zones spécifiques sans délai important (notamment utile lorsque la Charte est déclenchée).
La constellation Pléiades est conçue pour répondre aux applications de télédétection en Très Haute Résolution (THR) :
- mise à jour des bases de données cartographiques de l’IGN (Institut Géographique National).
- élaboration des plans de prévention des risques (cette application rentre dans le cadre du stage).
- suivi des bonnes pratiques européennes (directive-cadre eau, nitrate, pratiques environnementales en agriculture, politique agricole commune, etc.).
- suivi de la déforestation illégale et gestion de la production sylvicole.

Figure 4 – Illustration simplifiée de la structure des satellites Pléiades 1A et 1B, composés de 3 panneaux solaires, d’un baffle, de plusieurs miroirs en position Cassegrain, d’un radiomètre et d’antennes en bandes X et bandes S pour la transmission des données et l’acquisition des instructions de vol depuis les stations au sol. Crédits : ASTRIUM
Les deux satellites possèdent un radiomètre en TDI (voir Section III.1.a) avec deux modes spectraux : panchromatique (noir & blanc) et multibande (couleurs). Ces deux modes permettent une acquisition des images avec une résolution de 70 cm pour le panchromatique et 2,8 m pour le multibande (voir Figure 5).
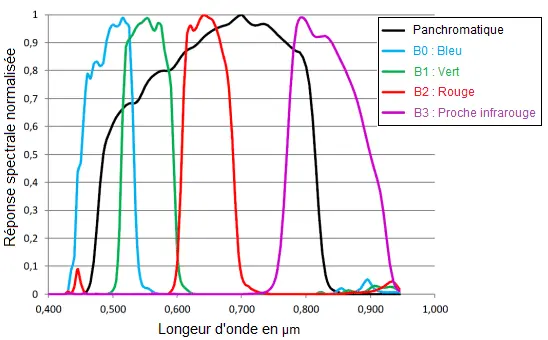
Figure 5 – Bandes passantes spectrale du radiomètre de Pléiades. Crédits : Hedhli, I., et al., 2017 [6]
Il est possible d’obtenir des images en couleur d’une résolution de 50 cm grâce à la technique de pansharpening. Cette technique permet la fusion d’images multispectrales panchromatiques haute résolution et basse résolution pour créer une seule image couleur haute résolution (voir Figure 6). Pour cela, on rééchantillonne les bandes multispectrales basse résolution pour les rendre superposables à l’image panchromatique haute résolution. Puis, on filtre en basse fréquence la bande panchromatique dont le contenu fréquentiel est proche de celui des bandes multispectrales. On fait ensuite la multiplication des pixels multispectraux.

Figure 6 – Processus de fusion panchromatique/multispectrale sur une image Pléiades. L’image fusionnée est composée de l’information spectrale des 4 bandes dans le produit panchromatique à une résolution de 50 cm. Crédits : CNES/ONERA/IGN
III.3 - Détection de changement optique par deep learning
a) La théorie du deep learning
Le deep learning, ou apprentissage profond, consiste à apprendre des représentations de haut niveau des données en utilisant des réseaux de neurones. Ce concept a été développé dans les années 1980, mais a été rapidement abandonné par manque de puissance de calcul et de données. Grâce à l’apparition des nouvelles techniques d’optimisation, le deep learning a permis d’obtenir des performances exceptionnelles pour différentes tâches :
- La classification d’images : Le plus souvent, à l’aide de réseaux convolutionnels.
- La segmentation d’images : Différentes architectures permettent d’attribuer des étiquettes de classe pour chaque pixel de l’image. Nous allons principalement étudier le fonctionnement de cette méthode durant la suite du rapport (voir Section III.3.b).
- La reconnaissance d’objets : Les réseaux sont capables d’identifier et de localiser dans une image ou une vidéo en dessinant des boîtes englobantes autour d’eux.
- Les modèles génératifs : Utilisation de réseaux antagonistes génératifs ou Generative Adversarial Networks (GANs) permettant de générer des images réalistes à partir d’une image de bruit, d’apprendre à générer des données d’entraînement ou encore de générer des images à partir d’un texte.
Le deep learning, qui est un sous-groupe du machine learning, se base sur la généralisation des données à partir d’algorithmes statistiques. Les algorithmes de deep learning se reposent uniquement sur l’entraînement d’architectures de réseaux de neurones artificiels avec plusieurs couches à partir d’un jeu de données. Le plus important lors de l’entraînement d’un réseau de neurones est de s’assurer que le jeu de données soit de qualité, qu’il y ait assez de données pour représenter l’ensemble des solutions possibles afin d’éviter les pièges et le sur-apprentissage.
Comme nous l’avons vu précédemment les ressources computationnelles jouent un rôle crucial dans la réalisation de tâches en deep learning sur des ensembles de données volumineuses et complexes. Les unités de traitement graphique (ou GPU) ont révolutionné le domaine en permettant un traitement parallèle massif, accélérant considérablement l’entraînement des modèles par rapport aux unités centrales de traitement (ou CPU) traditionnelles. Les GPUs sont particulièrement efficaces pour les opérations matricielles intensives, ce qui en fait un choix privilégié pour le deep learning. Le CNES possède un calculateur à haute performance (ou HPC), qui met à dispositions des noeuds de calcul GPU très performants pour l’entraînement de réseau de neurones.
Parallèlement à ces avancées matérielles, des frameworks logiciels tels que TensorFlow, Pytorch,
et Keras ont largement facilité le développement, l’entraînement et le déploiement des modèles de
deep learning. TensorFlow, développé par Google, est l’un des frameworks les plus utilisés pour sa
flexibilité et PyTorch, de Facebook, est apprécié pour sa simplicité d’utilisation et sa dynamique de
calcul. Durant ce stage, j’ai pu utiliser ces deux frameworks mais Pytorch offre plus de maniabilité
sur le développement de modèles. Mais avant de rentrer dans les détails d’architectures de réseaux
de neurones, nous allons essayer de comprendre comment fonctionne un neurone.
Fonctionnement général d’un réseau de neurones :
Des bases sur le fonctionnement d’un réseau de neurones sont données en Annexe B. On initialise dans un premier temps les poids et les biais du réseau souvent de manière aléatoire ou à l’aide de modèles pré-entraînés. Ensuite, il y a la phase d’entraînement (ou training) qui permet aux données d’entraînement d’être introduites dans le réseau par lot (ou batch en anglais). Pour chaque lot, le réseau effectue une propagation avant pour produire une prédiction. La fonction de perte est calculée pour évaluer l’erreur et la rétropropagation ajuste les poids en fonction de l’erreur. Ce processus est répété pour de nombreux cycles (époques) jusqu’à ce que le réseau atteigne une performance satisfaisante.
Un ensemble de données de validation est utilisé pour évaluer la performance du modèle sur des données non vues pendant l’entraînement. Ce processus aide à détecter le surapprentissage (overfitting) et à ajuster les hyperparamètres.
Une fois le modèle entraîné, il est testé sur un ensemble de test indépendant pour évaluer sa performance finale. Des métriques permettent d’évaluer les propriétés et les performances du réseau comme l’exactitude (accuracy), la précision (F1 score), la capacité à identifier (recall) et la similarité entre deux ensembles (Intersection over Union score ou IoU) pour les tâches de classification notamment. Durant ce stage, nous allons uniquement nous intéresser à l’évolution de la métrique IoU car c’est l’une des métriques les plus utilisées pour refléter des bonnes performances lors du problème de segmentation (voir Section III.3.b).
Le score IoU, ou Jaccard index, mesure la similarité entre le masque prédit et le masque réel
en calculant le rapport entre l’intersection et l’union de ces deux ensembles. Il est souvent utilisé
pour évaluer les modèles de segmentation car il prend en compte à la fois les vrais positifs et les
faux positifs, fournissant ainsi une évaluation équilibrée de la performance.
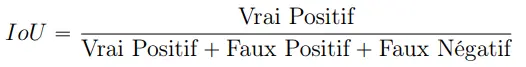
b) La segmentation d’images
Comme nous l’avons vu dans la section précédente, l’apprentissage des réseaux de neurones peut permettre de résoudre des problèmes non linéaires et complexes comme la segmentation d’images. Nous allons différencier deux types de tâches différentes : la segmentation sémantique binaire et la segmentation sémantique multiclasse.
Segmentation sémantique binaire :
La segmentation sémantique binaire consiste à classer chaque pixel d’une image en une classe prédéfinie. Cela revient à dire que l’on donne une étiquette à chaque pixel que l’on considère appartenir à cette classe (voir Figure 7). Il est donc important d’effectuer un prétraitement des données notamment en fournissant des images avec des masques associés contenant uniquement des 0 ou des 1 (la valeur 0 signifie que le pixel n’appartient pas à la classe et la valeur 1 signifie que le pixel appartient à la classe). C’est sûrement la tâche la plus difficile et la plus longue à faire car elle n’est pas automatique et pas exacte car l’humain peut se tromper sur sa notation.
Une fois le jeu de données complet, environ des centaines ou des milliers d’images et de masques,
celui-ci est présenté à l’architecture du réseau de neurones. Plusieurs techniques telles que les
rotations, les translations, les zooms, et les transformations de couleur peuvent être ajoutées pour
augmenter la diversité des données et améliorer la robustesse du modèle pendant l’entraînement.
On appelle ce processus la data augmentation (voir Section IV.1.c).

Figure 7 – Principe montrant la création d’un jeu de données pour la segmentation sémantique binaire avec une image satellite à gauche, et son masque de vérité associé à droite, montrant tous les endroits où il y a un bâtiment sur l’image. Le masque est donc uniquement composé de valeurs de pixel 0 pour le background et 1 lorsque le pixel est un bâtiment.
Segmentation sémantique multiclasse :
Tout comme la segmentation sémantique binaire, la segmentation sémantique multiclasse consiste à classer chaque pixel d’une image en une classe prédéfinie. Mais la différence est que nous n’avons plus des masques binaires mais maintenant des masques contenant des valeurs de pixels allant de 0 jusqu’à N-1, où N est le nombre de classes. La segmentation sémantique multiclasse va donc plus loin que la segmentation sémantique binaire en distinguant plusieurs classes au sein d’une même image. La préparation des masques de vérité est donc encore plus longue car plus complexe à réaliser. Une fois le jeu de données complet, celui-ci est présenté à l’architecture du réseau de neurones qui est un peu plus complexe et grand que l’architecture pour la segmentation sémantique binaire car la tâche est plus complexe. Néanmoins, on peut utiliser aussi des techniques de data augmentation sur les données d’entraînement afin d’améliorer les performances de notre modèle.
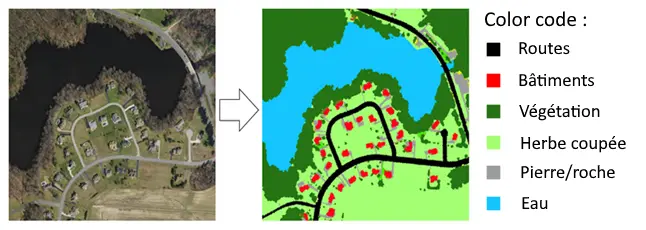
Figure 8 – Principe montrant la création d’un jeu de données pour la segmentation sémantique multiclasse avec une image satellite à gauche et son masque de vérité associé à droite montrant ce que l’on souhaite classer dans l’image. Le masque ici possède 6 classes : routes (0), bâtiments (1), forêts/végétation (2), Herbe coupée (3), pierre (4) et eau (5).
Architectures des réseaux de segmentation :
Les architectures de réseau de neurones pour la segmentation sémantique binaire ou multiclasse possèdent globalement la même structure avec un encoder, un decoder et des connections skip. Le rôle de l’encodeur est d’extraire des caractéristiques à partir de l’image d’entrée. Le décodeur prend les caractéristiques extraites et les transforme en une carte de segmentation de la même taille que l’image d’entrée. Pour cela on utilise des convolutions transposées, d’interpolations bilinéaires ou des couches de dé-convolution. Enfin, les connections skip permettent de combiner des caractéristiques de résolution fine de l’encodeur avec des caractéristiques de niveau plus élevé du décodeur, ce qui aide à récupérer des détails précis. Techniquement au plus un réseau de neurones est profond avec de nombreux paramètres et de poids ajustables, au plus il sera capable de récupérer les détails précis de l’image, au plus il sera long à entraîner. Nous essayerons de démontrer que c’est le cas dans la Section IV.1.b.
Le réseau permettant de faire de la segmentation sémantique le plus simple possible se repose
sur un réseau de neurones convolutifs (CNN) comme SegNet ou UNet, voir architecture en Figure 9. Chaque bloc de convolution (en bleu) dans le réseau SegNet comporte plusieurs couches de
convolution avec de petits filtres (3x3) et une activation ReLU. Après chaque bloc, une couche de
pooling max (en vert) réduit la dimension spatiale des caractéristiques tout en conservant l’essentiel
des informations. SegNet stocke les indices de pooling pour les utiliser lors de l’upsampling (en
rouge), permettant ainsi une reconstruction précise de l’image. Après l’upsampling, des couches
de convolution affinent les caractéristiques pour une segmentation précise. Enfin, une couche de
convolution suivie d’une activation softmax génère les probabilités de classe pour chaque pixel,
produisant une segmentation sémantique de l’image.
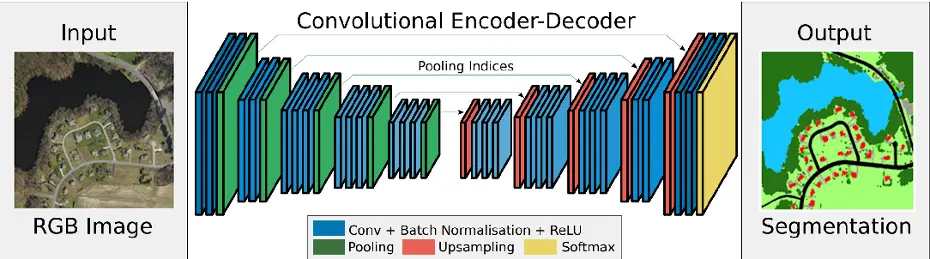
Figure 9 – Architecture du réseau SegNet sur les bases d’un réseau convolutionnel permettant de faire de la segmentation sémantique le plus simplement possible. On retrouve la partie encodeur qui extrait les caractéristiques de l’image et la partie décodeur qui les transforment en un masque de segmentation (binaire ou multiclasse). Crédits : Vijay Badrinarayanan et al. (2015) [1]
Les architectures plus complexes introduisent plusieurs avancées comme l’utilisation d’atrous de convolutions, de modules ASPP (Atrous Spatial Pyramid Pooling), de mécanismes d’attention, etc, qui permettent de mieux gérer les informations et donc offrent une meilleure performance sur des tâches de segmentation difficiles. Dans la suite, on s’intéressera plus particulièrement aux architectures MAnet et DeepLabV3+, qui sont des architectures plus complexes et plus gourmandes en ressources que les réseaux convolutifs basiques mais plus performants pour la segmentation sémantique d’images.
IV - Résultats
IV.1 - Détection de changement des bâtiments par segmentation sémantique binaire
L’objectif est de créer un réseau de neurones capable de reconnaître les bâtiments dans les images de Pléiades prises dans le cadre de la Charte après le tremblement de terre en 2023 à Kahramanmaraş en Turquie. Le principal défi est de pouvoir entraîner un réseau de neurones uniquement avec des données open source (accessibles par tout utilisateur) et d’en suite vérifier qu’il est possible de faire de la transférabilité sur des images Pléiades qui sont des images d’acquisitions différentes (pas la même exposition, pas la même résolution...). Nous visons à démontrer la capacité d’un réseau de neurones à s’adapter d’une image à une autre, même si le capteur d’acquisition est différent, car, dans le cadre de la Charte, nous sommes confrontés à obtenir des images venant de satellites différents. Une fois le réseau de neurones bien entraîné, les poids pourront être réutilisés par la communauté scientifique pour l’utiliser sur d’autres images Pléiades.
a) Données open source du challenge Xview2
Dans un premier temps, nous allons entraîner nos réseaux sur des données open source issues du challenge Xview2 [14]. Ce challenge a pour but de lancer la création de modèles d’apprentissages automatiques sur la base d’un jeu de données xBD [5], qui évaluent les dommages des bâtiments à partir d’images satellites avant et après une catastrophe naturelle. Les données xBD fournissent des informations sur 8 catastrophes survenues dans 15 pays (voir Figure 10). De plus, elles offrent une échelle d’évaluation des dommages aux bâtiments dans une image satellite (échelle allant de 0 pour un bâtiment intact à 4 pour un bâtiment totalement détruit). L’ensemble du jeu de données contient 22 068 images en couleurs de 1024 x 1024 pixels. Nous allons donc entraîner nos réseaux de neurones sur des images de 512 x 512 pixels (une grande image séparée fait 4 petites images), avec les 3 canaux RVB et prendre uniquement les masques contenant des bâtiments (matrice non nulle) et les bâtiments intacts (uniquement l’échelle entre 0 et 1 lors de la labellisation).
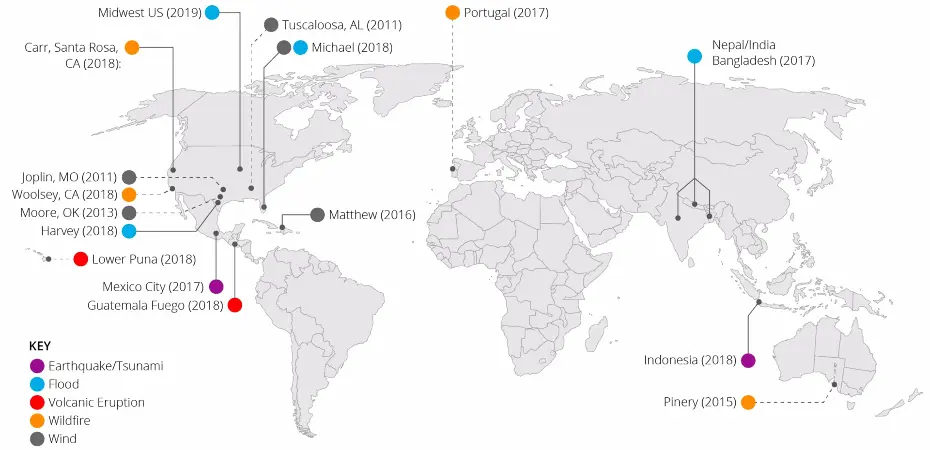
Figure 10 – Carte montrant les différents endroits du monde où il y a des images avant et après la catastrophe naturelle dans le jeu de données fourni par xView2 à l’aide des satellites de l’entreprise MAXAR. Crédits : xView2 [14]
b) Comparaison des architectures de réseau de neurones
Une fois le jeu de données prêt, nous pouvons construire l’architecture du réseau de neurones et le pipeline d’entraînement, de validation, et de sauvegarde des poids. J’ai utilisé Pytorch-lightning pour simplifier les boucles d’entraînement de Pytorch, ainsi que Tensorboard pour visualiser les images et suivre les performances du réseau durant l’entraînement et la validation.
Nous allons prendre un jeu de données de plus de 1000 images fournies par le challenge xView2
(voir Section IV.1.a), puis nous allons les présenter à différentes architectures de réseau de neurones. J’ai
implémenté des architectures CNN (comme vu à la Figure 9) avec plus ou moins de paramètres
d’entraînement (allant de 9,1 millions de paramètres à 581 millions). Je me suis ensuite aidé de la
librairie segmentation_model_pytorch pour implémenter des architectures plus complexes mais qui
sont adaptées au problème de segmentation sémantique. En utilisant ce même jeu de données, nous
examinerons l’évolution du score IoU (voir Section III.3.a) à travers les différentes architectures, car
notre objectif est d’obtenir un réseau capable de prédire avec précision les masques de bâtiments
à partir d’images satellites Pléiades (donc un jeu de données différent).

Figure 11 – Graphiques montrant l’évolution de la métrique IoU lors de la validation des différentes architectures sur le jeu de données Pléiades sans initialisation de poids, avec à gauche les résultats pour les CNNs et à droite pour les architectures plus complexes.
Comme montré à la Figure 11, les architectures de réseaux de neurones apprennent différemment sur un même jeu de données. Pour les CNN, l’augmentation des paramètres n’améliore pas toujours les performances. Un compromis existe entre un score IoU élevé et le nombre de paramètres. Tandis que les architectures complexes atteignent un score IoU plus élevé et apprennent plus rapidement. Par conséquent, nous nous concentrerons uniquement sur l’utilisation d’architectures complexes par la suite, afin d’obtenir de meilleures prédictions (tout en minimisant le temps d’entraînement). La variabilité des graphiques de validation montre la difficulté de convergence sur un jeu de données différent, que nous allons tenter de résoudre dans les prochaines sections.
c) Augmentation de données
Afin de pouvoir augmenter les scores des différentes métriques et aussi la fiabilité, la robustesse et la précision de notre réseau de neurones, en vue de pouvoir le tester sur des données Pléiades, j’ai mis en place de l’augmentation de données ou data augmentation en anglais.
Comme vu dans la Section III.3.b, la data augmentation est une technique permettant d’appliquer plusieurs transformations géométriques ou radiométriques aléatoires à chaque lot d’entraînement afin que le réseau ne voit jamais deux fois la même image. Cela revient à dire que l’on augmente artificiellement le nombre d’images que voit le réseau pour ne pas qu’il s’habitue, par exemple, à voir un bâtiment tout le temps dans la même position, de la même forme ou de la même couleur. Il est important de choisir avec soin les transformations appliquées, en veillant à ce qu’elles restent aussi "réalistes" que possible, étant donné que nous travaillons avec des images satellites. Cela signifie qu’il faut éviter les déformations, les jeux de perspective, les inclinaisons ou les torsions. En revanche, nous pouvons appliquer des rotations, des translations, ajouter du flou gaussien (pour simuler un changement de résolution), ajuster le contraste ou la luminosité, et introduire des variations radiométriques sur les bandes RVB, entre autres.
On observe donc l’impact de ces transformations, lors de la phase de validation composée uniquement de données Pléiades (images et masques de bâtiments intacts binaires) disponibles sur la ville de Toulouse. J’ai donc une phase d’entraînement, sur des données open source xView2 avec de l’augmentation de données et une phase de validation sur des données Pléiades afin de s’assurer que la transférabilité fonctionne. Nous appliquons diverses transformations (radiométriques et géométriques) lors d’un nouvel entraînement du réseau MAnet, choisi en Section IV.1.b, et comparons les scores IoU obtenus (voir Figure 12).
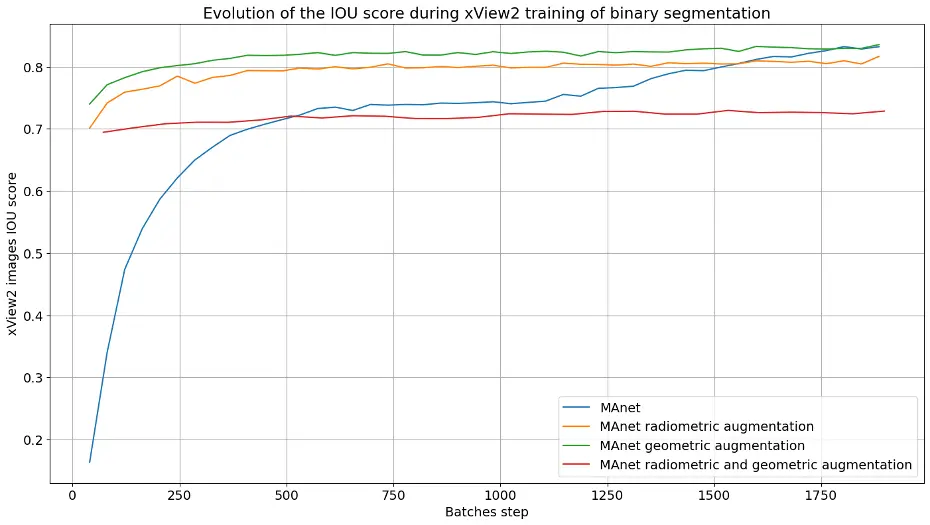
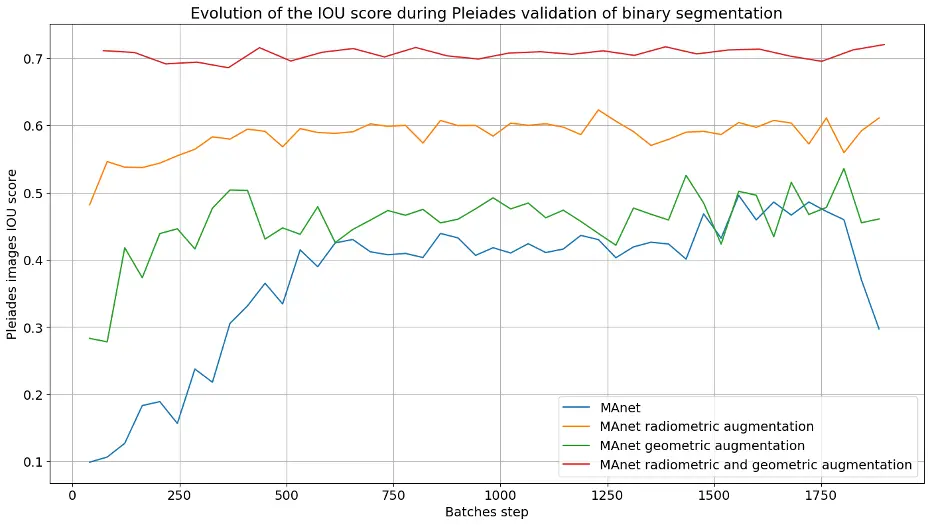
Figure 12 – Graphiques montrant l’évolution de la métrique IoU lors de l’entraînement sur xView2 et la validation sur un jeu de données Pléiades avec différentes augmentations de données.
On remarque, lors de la phase de validation sur les données Pléiades, que le réseau MAnet arrive à augmenter son score IoU de plus de 30 % lorsque l’on rajoute de la data augmentation sur le jeu d’entraînement xView2. Ce résultat montre la faisabilité de pouvoir faire de la transférabilité entre plusieurs images de satellites différents et de capteurs différents. Pour la suite, on se proposera d’appliquer ces mêmes transformations géométriques et radiométriques lors des prochains entraînements d’architectures, afin de maximiser le score IoU sur les données Pléiades.
Nous allons ensuite réaliser plusieurs entraînements sur le même jeu de données, en appliquant
diverses transformations radiométriques (en plus des transformations géométriques), afin d’observer si certaines de ces transformations améliorent le score IoU sur la validation Pléiades (voir
Figure 13).
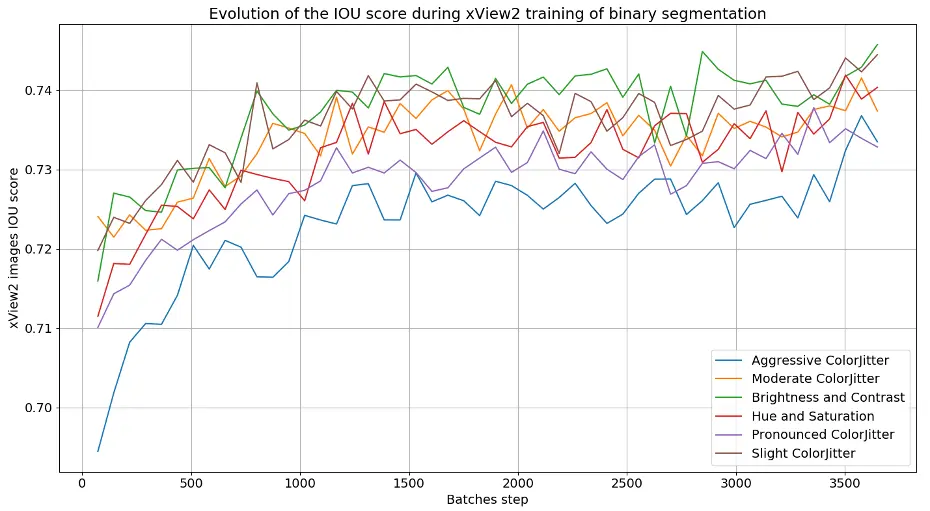
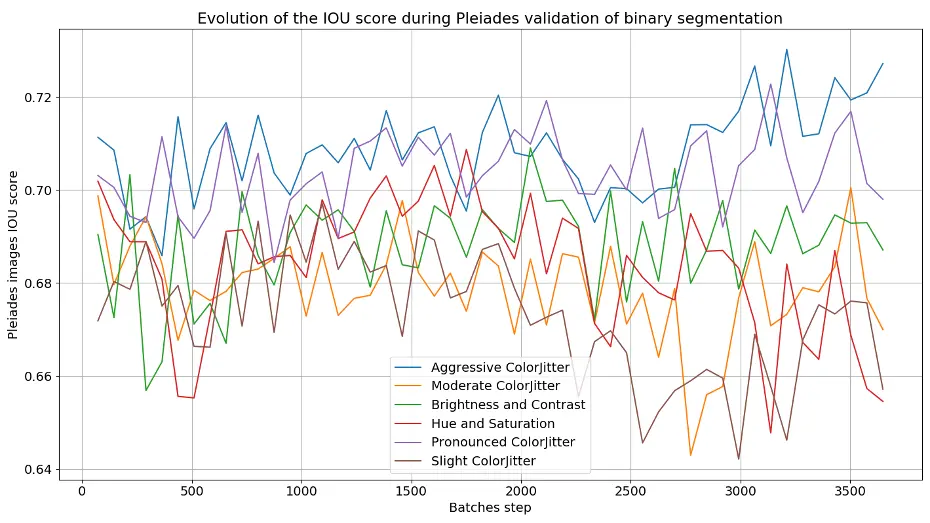
Figure 13 – Graphiques montrant l’évolution de la métrique IoU, lors de l’entraînement de l’architecture MAnet sur le jeu de données xView2 avec initialisation de poids et différentes augmentations de données à gauche, et la validation sur des images Pléiades sans augmentations de données à droite.
On remarque que pour une même architecture de réseau de neurone, un même jeu de données et avec des transformations aléatoires différentes, le score IoU n’évolue pas de la même manière. Cela montre la grande variabilité au niveau des résultats car c’est une tâche complexe que de vouloir passer d’un jeu de données à un autre. Néanmoins, nous obtenons des meilleurs score d’IoU sur Pléiades lorsque l’on applique de fortes transformations radiométriques (luminosité, contraste, saturation et teinte). Ces transformations radiométriques, Aggressive ColorJitter, seront appliquées lorsque nous ferons de prochains entraînements avec augmentation de données.
Un autre résultat significatif, observé dans l’évolution du score IoU sur les données xView2 ou Pléiades, est que le réseau semble détecter moins de 80 % des bâtiments intacts dans une image. Il est, en effet, difficile d’obtenir des scores plus importants lors de la segmentation sémantique d’images satellites en raison de la grande diversité de caractéristiques (bâtiments, végétation, routes, etc.), des textures différentes et sous diverses conditions lumineuses. Les bords entre les classes (par exemple, entre un bâtiment et une route adjacente) peuvent aussi être flous ou mal définis dans les images satellites. Cela conduit à des erreurs de classification près des bords, réduisant la précision globale et donc le score IoU. Des masques imparfaits ou imprécis peuvent aussi réduire artificiellement le score IoU, même si le modèle fonctionne bien. Donc, un score IoU de 0,73 est déjà considéré comme excellent dans ce contexte, et dépasser ce seuil pourrait être extrêmement difficile sans améliorations significatives des données, des modèles, ou des techniques de post-traitement.
Après plusieurs heures d’entraînements, le réseau de neurone MAnet avec un encoder efficientNetb7 et une fonction de perte "Combinée" (Dice loss et Binary Cross-Entropy), qui est une fonction
plus stable numériquement et plus efficace pour les tâches de segmentation binaire, obtient un
score IoU de convergence 0,73 sur des données Pléiades. Ce réseau sera utilisé dans la Section IV.2.d.
d) Correspondance d’histogramme et normalisation
Nous allons maintenant nous intéresser à l’étude de correspondance d’histogramme et de normalisation. En effet, dans le cadre de la transférabilité multi-capteur, nous pouvons être amené à avoir des images n’ayant pas les mêmes normalisations ou les mêmes sensibilités radiométriques. Dans cette section, nous allons examiner si le pré-traitement des données améliore les performances du réseau MAnet sur les données de validation Pléiades.
La correspondance d’histogramme ou histogram matching est une technique qui ajuste l’histogramme de chaque canal d’une image pour qu’il corresponde à l’histogramme d’une image de référence. Cela permet de normaliser les images provenant de différentes sources ou capteurs afin qu’elles aient des distributions similaires. La normalisation par percentiles implique le redimensionnement des valeurs des pixels d’une image en fonction de certains seuils (comme le 1er et le 99e percentile). Cette méthode permet de réduire l’influence des valeurs extrêmes ou des outliers en comprimant la plage dynamique des pixels. La normalisation statistique consiste à soustraire la moyenne des pixels de chaque image puis à diviser par l’écart-type, de sorte que l’image normalisée ait une moyenne de 0 et un écart-type de 1.
Nous allons ensuite réaliser plusieurs entraînements sur le même jeu de données, en appliquant diverses normalisations sur les images xView2 mais aussi sur les images Pléiades de validation (voir Figure 14).
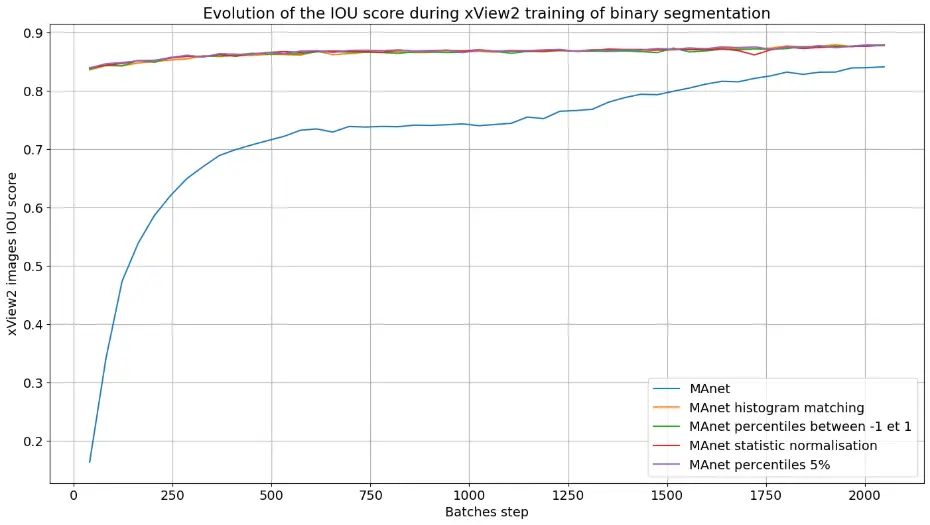
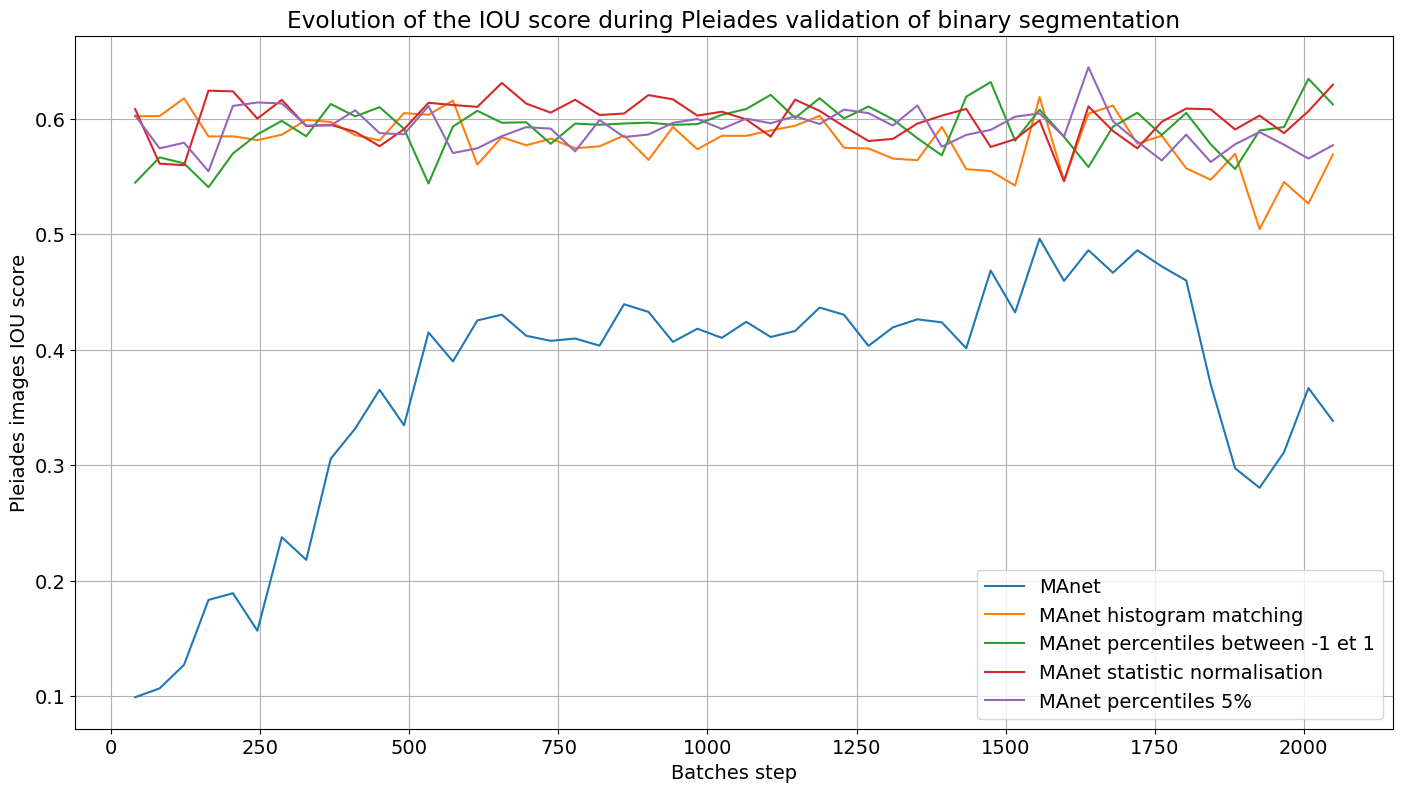
Figure 14 - Graphiques montrant l’évolution de la métrique IoU, lors de l’entraînement de l’architecture MAnet sur le jeu de données xView2 avec initialisation de poids et différentes normalisations à gauche, et la validation sur des images Pléiades normalisées à droite.
On constate que la normalisation améliore le score IoU sur les données Pléiades de 0,1, ce qui démontre son potentiel pour augmenter ce score. Elle permet également une convergence plus rapide, car les données deviennent rapidement comparables. Cependant, cette convergence se stabilise autour d’un score de 0,6, tandis que l’augmentation de données a permis d’obtenir des scores plus élevés. Un des inconvénients de la normalisation ou de l’histogram matching est qu’elles peuvent entraîner la perte de caractéristiques importantes pour la détection. Ainsi, le choix de la méthode de normalisation ou de prétraitement doit être adapté à la nature des données et aux besoins spécifiques de la tâche. Pour la suite, nous utiliserons uniquement des techniques d’augmentation de données, car elles se sont révélées plus efficaces pour la transférabilité sur des images Pléiades.
e) Application sur les données de la Turquie
Une fois qu’un réseau de neurone est assez entraîné et qu’il possède des bonnes performances, nous pouvons l’utiliser sur des images jamais vues, comme par exemple les images au nadir, prises avant et après le tremblement de terre en Février 2023 à Kahramanmaraş (voir Figure 15). Les images Pléiades de la Turquie sont en RVB, de taille (1024,1024) et sont présentées en entrée du réseau.

Figure 15 - Images de validation Pléiades avant et après le tremblement de terre en Février 2023 à Kahramanmaraş avec les prédictions du réseau MAnet, entraîné sur les données xView2. Les zones rouges de l’image de détection de changements est obtenue en soustrayant le masque de prédiction des bâtiments avant la catastrophe du masque de prédiction après la catastrophe.
Lorsque l’on applique le réseau de segmentation binaire sur les images de la Turquie, on obtient des cartes de prédiction binaire des bâtiments intacts pour chaque image. L’avantage de cette prédiction c’est que nous obtenons une carte relativement fiable de tous les toits des bâtiments sur des images satellites Pléiades.
En effet, avec un score IoU de 0.73 sur des données Pléiades, on remarque que le réseau arrive
à capturer tous les bâtiments dans les deux images avant et après la catastrophe. Donc, si l’on
fait la soustraction entre le masque de prédiction avant le tremblement de terre et le masque de
prédiction après la catastrophe, nous obtenons une carte des bâtiments détruits (voir l’image à
droite de la Figure 15). On arrive à distinguer en rouge les emplacements manquants de certains
bâtiments, mais aussi à voir le décalage entre les deux images. En effet, les images avant et après
l’événement ne sont pas parfaitement alignées et un léger décalage peut entraîner l’apparition de
différences au niveau des contours des bâtiments intacts. Notre objectif est de pouvoir détecter le
plus rapidement possible les zones les plus touchées et non obtenir la forme parfaite du bâtiment,
mais il est possible d’utiliser plusieurs méthodes de filtrages (opérations morphologiques, filtrage
spatial...) sur le masque de détection de changement pour améliorer la prédiction.
IV.2 - Détection de changement des bâtiments par segmentation sémantique multiclasse
L’objectif est de pouvoir créer un réseau de neurones capable de reconnaître les bâtiments intacts, avec des faibles dégâts, avec des dégâts importants et les bâtiments détruits dans les images de Pléiades prises dans le cadre de la Charte après le tremblement de Terre en 2023 à Kahramanmaraş en Turquie. Le principal défi est donc de pouvoir entraîner un réseau de neurones capable de comparer 2 images en entrée (avant et après la catastrophe) et de déterminer les différentes classes de dégâts.
a) Les architectures siamoises
Afin de pouvoir répondre à cet objectif, je me suis intéressé à la construction d’une architecture de réseau de neurones siamoise (appelée ainsi car apprenant les représentations d’une paire d’image). Une architecture siamoise est donc composée de deux réseaux identiques (ou jumeaux) qui partagent les mêmes poids et paramètres. Ces sous-réseaux peuvent être des CNNs, comme vu dans la Section III.3.b. Chaque sous-réseau prend une entrée différente mais identique en terme de structure, ici les images doivent avoir les filtres RVB et la même dimension.
Il est désormais possible de modifier certaines architectures de la Section IV.1.b en architectures
siamoises : adapter l’entrée pour accepter deux images, réaliser des convolutions partagées puis
des concaténations pour les présenter au décodeur qui donnera en sortie la carte de changement.
J’ai modifié plusieurs réseaux mais je vais me concentrer sur l’architecture du réseau CNN siamois
(car architecture simple) et sur réseau DeepLabV3+ siamois (meilleures performances).
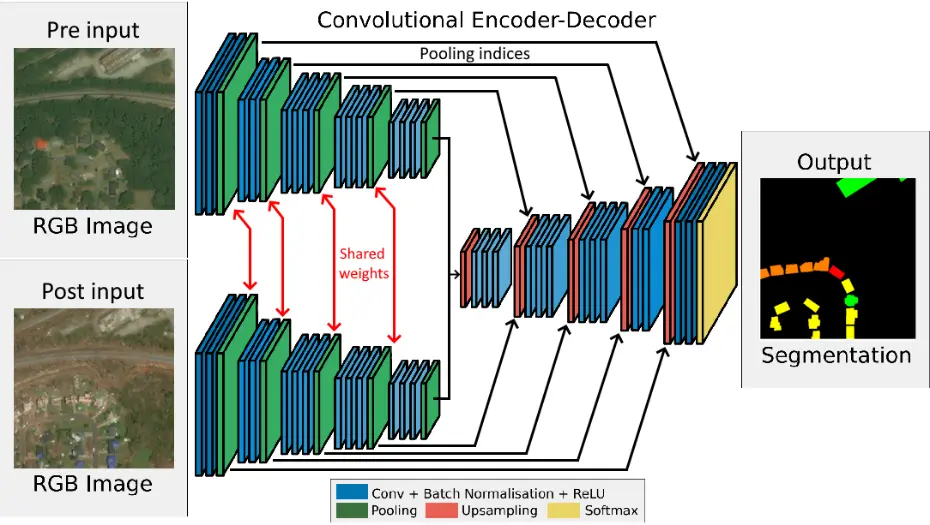
Figure 16 – Architecture du réseau SegNet siamois permettant de faire de la segmentation sémantique multiclasse en prenant en compte les caractéristiques des images avant et après la catastrophe. On retrouve deux parties encodeur qui se partagent les poids et donc extraient les caractéristiques des deux images et la partie décodeur qui les transforment en un masque de segmentation (binaire ou multiclasse).
Le réseau CNN siamois :
Pour modifier l’architecture CNN, nous devons adapter l’entrée pour qu’il y ait deux branches, afin de présenter au réseau une paire d’image RVB. Dans chaque branche, nous ajoutons des couches convolutionelles distinctes mais partageant les mêmes poids pour les deux images, ce qui permet au réseau d’extraire les caractéristiques des deux images de manière cohérente (voir Figure 16). On fusionne ensuite les caractéristiques extraites des deux branches par concaténation qui seront présentées à une couche de décision qui prendra l’information fusionnée pour l’interpréter. La sortie du réseau reste une carte de segmentation mais cette fois-ci avec 5 classes (background, bâtiment intact, peu de dégâts, beaucoup de dégâts, détruit).
Le réseau DeepLabV3+ siamois :
Pour modifier l’architecture DeepLabV3+ en réseau siamois nous devons adapter aussi l’entrée mais rajouter des convolutions atrous et les modules ASPP (Atrous Spatial Pyramid Pooling). Une convolution atrous est une technique utilisée pour augmenter le champ réceptif des filtres de convolution sans augmenter le nombre de paramètres et cela sert notamment à ne pas perdre de résolution. Les modules ASPP sont des ensembles de convolution atrous avec différents taux de dilation, suivi par une couche de pooling global et donc capable de capturer les caractéristiques essentielles. Tout comme le CNN siamois, les caractéristiques sont ensuite concaténées, envoyées dans l’encodeur et présentée à la couche de sortie pour prédire la carte de segmentation en 5 classes.
La fonction de perte contrastive :
Durant la phase d’entraînement, chaque sous-réseau détermine les représentations importantes des entrées qui sont ensuite comparées en calculant la distance euclidienne. La sortie de cette fonction est utilisée pour déterminer la similarité ou la différence entre les deux entrées originales. Il faut ensuite adapter la fonction de perte afin de pénaliser les paires d’entrées similaires avec des représentations différentes et les paires d’entrées différentes avec des représentations similaires. Pour cela on utilisera la fonction de perte contrastive :
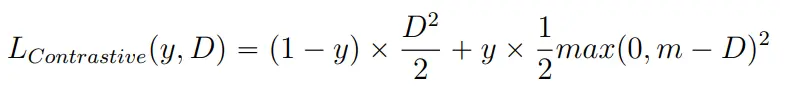
Avec D, la distance euclidienne entre les vecteurs de représentation des deux entrées, y, l’étiquette binaire indiquant la similarité (0 pour similaire sinon 1) et m, la marge fixée (un hyperparamètre) qui définit la distance minimum pour laquelle les paires dissemblables sont pénalisées. Si la distance entre les représentations de paires dissemblables est inférieure à m, la perte augmente.
b) Entraînement d’architectures siamoises
Une fois les architectures de réseau de neurones implémentées et modifiées, nous pouvons les entraîner grâce au jeu de données xView2 qui fournit des images RVB avant et après une catastrophe naturelle et avec des masques de vérité terrain multiclasse. La Figure 17 montre l’évolution des scores IoU durant l’entraînement et la validation sur un jeu de données xView2 (voir Section IV.1.a), sans augmentation de données, sur plus de 1000 images, pré et post-catastrophe pour plusieurs architectures siamoises. Nous ne pouvons pas faire de validation cette fois-ci sur Pléiades car nous n’avons pas de masques de vérité terrain multiclasse pour des paires d’images.
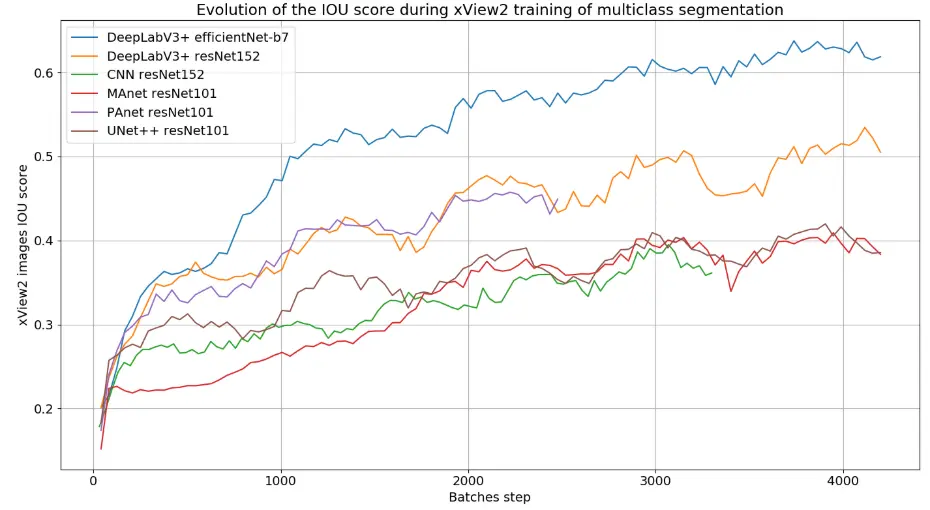
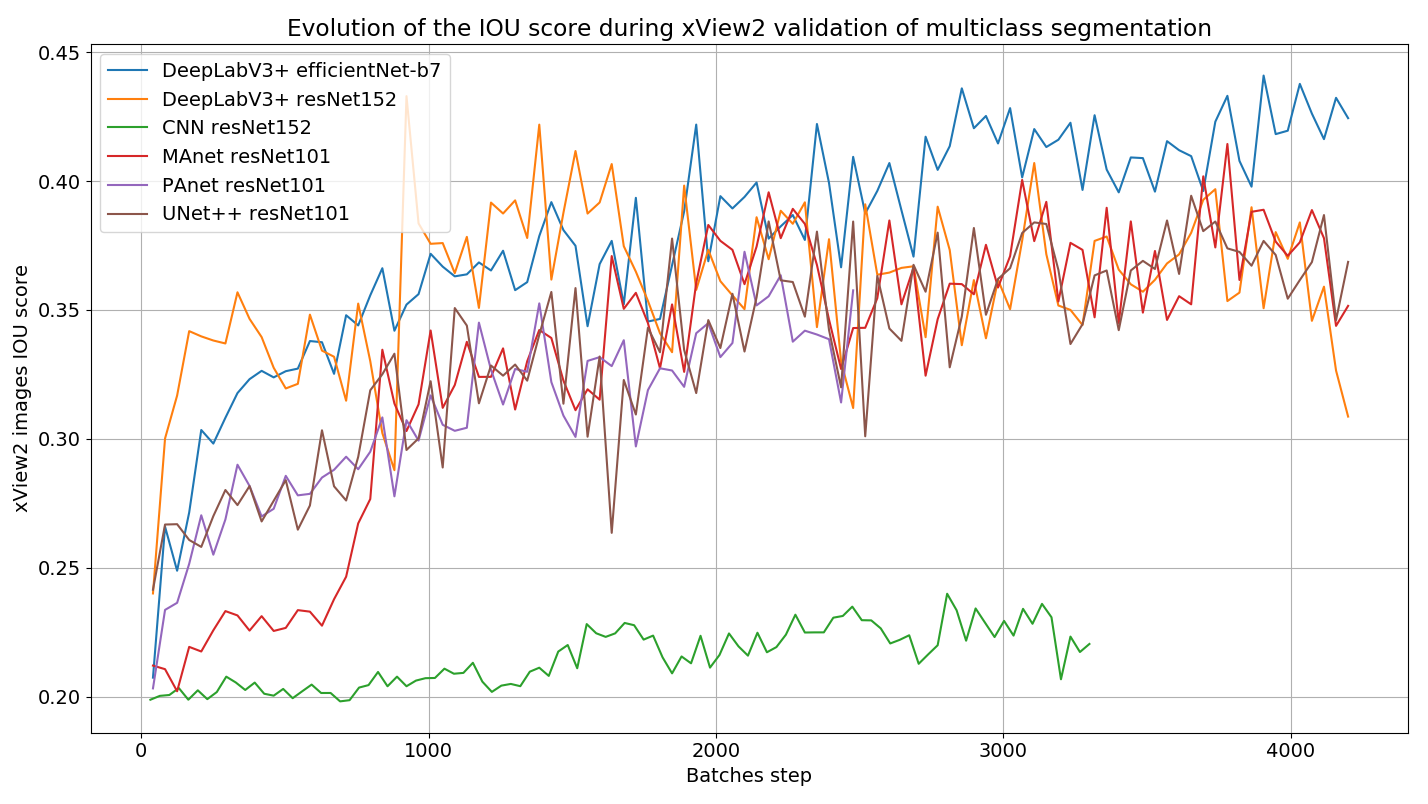
Figure 17 – Graphiques montrant l’évolution de la métrique IoU, lors de l’entraînement de différentes architectures siamoises sur le jeu de données xView2 sans augmentations de données à gauche, et la validation à droite.
Comme vu à la Section IV.1.b, les différentes architectures réagissent différemment pour un même jeu de données. On remarque que le réseau CNN a du mal à identifier les caractéristiques des images pré et post-catastrophe comparé aux architectures plus complexes. Après plusieurs tests et différents entraînements, c’est l’architecture siamoise DeepLabV3+ avec un encodeur efficientNet-b7, une fonction de perte "Contrastive" (voir Section IV.2.a) et de l’augmentation de données, qui obtient les meilleurs scores de métriques. Afin de pouvoir augmenter le score IoU et de pouvoir faire de la transférabilité sur des données Pléiades, j’ai appliqué les même transformations d’augmentation de données que vu à la Section c. Après de nombreuses heures d’entraînements, le réseau de neurone a obtenu un IoU total de 0,71 sur des données de validation xView2.
c) Application sur les données de la Turquie
Comme pour la segmentation sémantique binaire, j’applique les réseaux entraînés sur les images au nadir, prises avant et après le tremblement de terre en Février 2023 à Kahramanmaraş (voir Figure 18). Les images Pléiades de la Turquie sont en RVB, de taille (1024,1024) et sont présentées en entrée du réseau siamois DeepLabV3+, entraîné avec de l’augmentation de données et avec un score IoU total de 0,71.

Figure 18 – Images de validation Pléiades avant et après le tremblement de terre en Février 2023 à Kahramanmaraş avec les prédictions du réseau siamois DeepLabV3+, entraîné sur les données xView2. Le réseau siamois donne un masque de prédiction avec 5 classes : background (0) en noir, bâtiments intacts (1) en rouge, bâtiments avec de faibles dégâts (2) en vert, bâtiments avec d’importants dégâts (3) en bleu et bâtiments détruits (4) en jaune.
Lors de l’application du réseau siamois sur les images de la Turquie, nous obtenons une carte de segmentation multiclasse classifiant les bâtiments de l’état intact à détruit. L’avantage de cette prédiction est la génération directe d’une carte de changement riche en informations, incluant non seulement les bâtiments détruits, mais aussi ceux endommagés.
Avec un score IoU total de 0.71 sur des données xView2, représentant la moyenne de l’IoU pour chaque classe de segmentation, le réseau parvient à capturer certains bâtiments détruits, comme observé dans la Section e dans les données Pléiades. Ce score, bien qu’encourageant, montre que le réseau peut encore être optimisé pour améliorer sa précision. Cependant, le réseau ne détecte pas tous les bâtiments de l’image, ce qui pourrait être dû à plusieurs facteurs : une architecture sous-optimale, un sous-apprentissage, un surapprentissage, ou la complexité excessive de la tâche de détection de changement.
L’incapacité d’un réseau siamois à détecter tous les bâtiments peut indiquer des limitations dans l’architecture du réseau à exécuter la tâche de segmentation sémantique multiclasse. En effet, il manque des données Pléiades avec des masques multiclasse pour réaliser une évaluation complète et déterminer si le réseau fait de bonnes ou mauvaises prédictions, contrairement à ce que nous avons pu faire avec la segmentation sémantique binaire. Le réseau demeure une véritable "boîte noire", et seule une évaluation humaine peut valider ses prédictions. Tout comme la segmentation sémantique binaire, la diversité des caractéristiques ou encore les masques imparfaits (on peut se poser la question de qu’est ce qui définit qu’un bâtiment soit plus endommagé qu’un autre sur une image satellite) ou imprécis peuvent réduire ce score IoU et donc la précision du modèle.
Pour aller plus loin, plusieurs tests pourront être réalisés avec différentes architectures siamoises et surtout différents hyperparamètres afin d’augmenter les scores des métriques d’évaluation et rendre le réseau plus fiable. Il est également envisageable d’inclure des images Pléiades avant et après la catastrophe dans l’entraînement, ce qui favoriserait la convergence du réseau. Cependant, le principal obstacle actuel est le manque de masques de labellisation pour ces données.
d) Le réseau de segmentation binaire :
Pour vérifier la détection de bâtiments détruits autrement qu’en validant sur des données en Turquie, pour lesquelles nous n’avons finalement pas de masque de vérité terrain, nous allons effectuer de la détection de changement sur un jeu de données xView2, qui est inconnu des deux réseaux (segmentation sémantique binaire et segmentation sémantique multiclasse). On sélectionne près de 350 images (pré et post-catastrophe) contenant au moins un bâtiment détruit et on associe à chaque paire d’images, un masque de bâtiments détruits uniquement.
Le réseau de segmentation binaire :
On applique ensuite le réseau MAnet de segmentation binaire (vu en Section IV.1) sur chaque image avant et après la catastrophe puis, par soustraction des deux masques, on obtient le masque de prédiction des bâtiments détruits (voir premier masque de la Figure 19). On calcule ensuite le score IoU entre le masque de vérité terrain (dernier masque de la Figure 19) et le masque de prédiction pour avoir le score de détection de changement.
Le réseau de segmentation multiclasse :
On applique ensuite le réseau siamois DeepLabV3+ de segmentation multiclasse (vu en Section IV.2.b) sur chaque paire d’images et on isole uniquement les prédictions pour la classe de bâtiments détruits (uniquement les zones en jaune sur le deuxième masque de la Figure 19). On calcule ensuite le score IoU entre le masque de vérité terrain et le masque de prédiction pour avoir le score de détection de changement.
Scores de détection de changement :
Sur plus de 350 paires d’images de catastrophes naturelles xView2, les scores de détection de changement moyens sont de 0,275 pour la segmentation binaire et de 0,287 pour la segmentation multiclasse. Ce sont finalement des scores très bas mais avec une meilleure prédiction pour le réseau multiclasse. Ce qui peut expliquer ce score c’est notamment la qualité des masques de vérité terrain qui ne sont pas parfaitement alignés avec la réalité, ce qui introduit une certaine incertitude dans les prédictions, mais aussi la limite des modèles à capturer les nuances spécifiques des changements de bâtiments dans des conditions diverses. Des méthodes telles que du filtrage morphologique, du test-time augmentation (augmentation de données sur les images de tests) ou de la prédiction multi-modèle peuvent augmenter ces scores.

Figure 19 – Images avant et après une tornade à Tuscaloosa, aux USA, issues des données xView2 avec les masques de détection de changement du réseau binaire MAnet, puis le réseau multiclasse DeepLabv3+ et le masque de bâtiment détruits de vérité terrain. La première ligne montre un cas où le réseau binaire prédit un masque de bâtiments détruits avec un IoU de 0,91 contre 0,39 pour le réseau siamois et la deuxième ligne montre un cas où le réseau siamois prédit un masque de bâtiments détruits avec un IoU de 0,92 contre 0,33 pour le réseau binaire.
Pour nuancer aussi ces scores de détection de changements très bas, il faut se rappeler que notre objectif était d’étudier la transférabilité sur des données Pléiades et non sur des données xView2. Nous n’avons pas forcément cherché à maximiser les scores IoU sur les données xView2 ce qui est aussi à prendre en compte dans notre interprétation de ces résultats.
IV.3 - Détection de bâtiments par segmentation sémantique pour des images dégradées
Le principal objectif de ce stage est de savoir si il était possible d’obtenir des informations par deep learning à partir d’une image dégradée de Pléiades. Mais avant de montrer la faisabilité de cet objectif, nous avons été obligés de savoir si la transférabilité entre différents capteurs était possible avant de s’intéresser à la transférabilité lors d’acquisitions différentes. Il était essentiel de démontrer que cette transférabilité multi-capteur était un pré requis nécessaire avant de tenter la détection dans des conditions d’acquisition différentes. En effet, comme vu à la Section II.1.d, nous obtenons finalement que très rarement des images prises au nadir et sans nuage. Cela a été notamment le cas lors du déclenchement de la Charte en Février 2023 à Kahramanmaraş, en Turquie [7]. Des images ont été prise dans l’urgence, et un des satellites Pléiades a dû changer son orientation pendant son orbite afin d’obtenir une image de Kahramanmaraş. Le satellite s’est orienté avec un angle d’inclinaison par rapport au nadir de 47° et d’une déviation latérale de -19° par rapport au plan principal de visée (voir à gauche de la Figure 20).

Figure 20 – Carte polaire, à gauche, montrant les angles d’inclinaison du satellite lors de l’acquisition de l’image de droite dans le cadre du déclenchement de la Charte, en Février 2023 à Kahramanmaraş, en Turquie. Trois régions différentes ont été étudiées afin d’évaluer les performances du réseau de neurone dans différentes conditions dégradées (très dépointées, nuageux et sombre)
J’ai choisi d’extraire trois sous-images représentant trois conditions différentes pour évaluer les performances des réseaux de neurones. L’objectif est d’entraîner un réseau suffisamment efficace pour détecter des bâtiments dans des conditions de fort dépointage (off-nadir) ou dans des conditions météorologiques défavorables (présence de nuages, variations d’exposition, etc.).
a) Détection de bâtiments sur des images dépointées (off nadir)
Nous allons d’abord examiner si le réseau de neurones MAnet, entraîné avec des données xView2 au nadir, parvient à détecter certains bâtiments sur des images Pléiades prises en off-nadir. Comme le montre le premier masque de prédiction de la Figure 21, le réseau échoue à reconnaître les bâtiments dans l’image. Cela démontre que le réseau est fortement dépendant des données d’entraînement et que, s’il n’a jamais été exposé à des images off-nadir, il est plus susceptible de faire des erreurs.
J’ai donc décidé de faire un nouvel entraînement MAnet mais avec cette fois-ci, des données
issues du challenge open source SpaceNet 4 [12]. Ce challenge fournit des images RVB prises avec
des angles variant de 7° à 54° (nadir à off nadir) grâce au satellite WorldView-2, avec des masques
de bâtiments intacts associés, de la ville d’Atlanta aux Etats-Unis en 2009.

Figure 21 – Image de validation Pléiades dans une zone très dépointée après le tremblement de terre à Kahramanmaraş avec les prédictions du réseau MAnet, entraîné sur des images au nadir sur les données xView2, avec de l’augmentation de données, puis avec le réseau MAnet, entraîné sur des images dépointées SpaceNet et de l’augmentation de données. Les zones vertes représentent les endroits que le réseau détecte comme étant un bâtiment dans l’image.
Après l’entraînement avec l’architecture MAnet sur un jeu de données xView2 et SpaceNet 4, avec en plus de l’augmentation de données qui donne les meilleurs scores sur des images au nadir avec Pléiades (voir Section IV.1.c), j’applique ce réseau sur les images de la Turquie dépointées (voir deux dernières images de la Figure 21). J’ai changé la fonction de perte pour cette tâche de segmentation binaire off nadir en passant de la fonction de perte "Combinée" à une fonction de perte de "Jaccard", qui me donne des meilleures performances d’IoU (cela a été aussi remarqué pour les architectures gagnantes du challenge SpaceNet [13]). Soient A le masque de prédiction binaire et B le masque de vérité terrain binaire, la fonction de perte de Jaccard est donnée par :
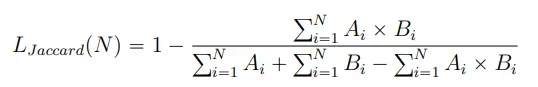
On remarque que le réseau arrive à bien prédire l’emprise de chaque bâtiment (toits et façades) sur l’image très dépointée, ce que n’arrivait pas à faire le réseau entraîné uniquement sur des images au nadir. Cela montre bien qu’il est possible de détecter des bâtiments dans une image off nadir prise par Pléiades grâce au deep learning. Il devient alors très difficile de détecter les changements, et donc d’obtenir des informations sur les bâtiments détruits à partir d’une image dépointée, car nous ne disposons pas d’images de la même zone capturées dans des conditions d’acquisition similaires (même angle de vue) avant la catastrophe. Pour l’instant, la reconnaissance de bâtiments intacts est l’une des seules informations que l’on peut obtenir d’une image dans des conditions dégradées.
On peut augmenter la fiabilité et les performances de ce réseau en intégrant, par exemple,
des données Pléiades prises au nadir ou en off-nadir pendant l’entraînement, en changeant plusieurs hyperparamètres (loss function, learning rate, architecture...) ou en développant un réseau
multiclasse capable de détecter distinctement les toits et les façades.
b) Détection de bâtiments dans des mauvaises conditions météorologiques
Comme pour la détection de bâtiments sur des images dépointées, on applique le réseau MAnet, entraîné avec des données xView2, avec augmentation de données, au nadir sur des images Pleiades off nadir et dans de mauvaises conditions météorologiques (voir les premiers masques de la Figure 22).
On remarque que le réseau arrive un peu à reconnaître des bâtiments à travers les nuages mais
il n’est pas très fiable. Je décide donc d’entraîner, une nouvelle fois, un réseau MAnet sur un jeu
de données différent de celui créé dans la Section IV.3.a. J’ai sélectionné uniquement des images avec
des nuages ou des mauvaises conditions météorologiques dans les données xView2. En effet, dans
ce jeu de données, j’ai réussi à obtenir plus de 800 images de bâtiments sous les nuages notamment
lors de feux de forêts, d’ouragans ou de tsunamis (voir Figure 10). J’ai ensuite utilisé les poids
d’entraînement du réseau précédent, en y ajoutant des images off nadir, afin d’améliorer la capacité
du réseau à détecter des bâtiments dans des conditions d’acquisitions difficiles.

Figure 22 – Images de validation Pléiades dans des zones nuageuses ou à faible exposition après le tremblement de terre à Kahramanmaraş avec les prédictions du réseau MAnet, entraîné sur des images, avec augmentation de données, au nadir sur les données xView2 puis avec le réseau MAnet, entraîné sur des images dépointées SpaceNet et des images nuageuses xView2. Les zones vertes représentent les endroits que le réseau détecte comme étant un bâtiment dans l’image.
Après avoir entraîné ce nouveau réseau MAnet sur le jeu de données enrichi, nous constatons une nette amélioration dans la détection des bâtiments à travers les nuages et une meilleure résistance aux variations d’exposition naturelle. Cela démontre qu’il est effectivement possible d’identifier des bâtiments dans des images de qualité dégradée. Cependant, la détection des changements reste un défi pour les mêmes raisons évoquées dans la section précédente.
Pour surmonter ces difficultés, il pourrait être utile d’explorer des approches supplémentaires,
comme l’incorporation de techniques de prétraitement plus avancées ou l’intégration de données
provenant de données Pléiades dépointées ou non, pour renforcer la robustesse du modèle face aux
variations des conditions d’acquisition.
V - Discussion
Tout d’abord, les objectifs du stage ont été atteints. J’ai exploré les différentes techniques de détection de changement de bâtiments suite à une catastrophe naturelle à l’aide du deep learning. L’entraînement réussi de modèles utilisant des données satellitaires open source et leur transférabilité aux données Pléiades illustrent non seulement leur potentiel pour la communauté scientifique, mais aussi leur capacité à généraliser la reconnaissance de bâtiments dans diverses images satellites. Ce résultat est important, car il démontre que ces modèles peuvent être mis à la disposition de la communauté scientifique et qu’ils parviennent à généraliser la reconnaissance de bâtiments ou de bâtiments détruits sur différentes images satellites. Cependant, il est important de noter que ces modèles de réseaux de neurones ne sont pas infaillibles et peuvent commettre des erreurs de prédiction. Bien que ces modèles puissent fournir des informations précieuses, ils ne remplacent pas l’expertise humaine et doivent être considérés comme des outils complémentaires, particulièrement utiles pour assister les labellisateurs dans leur travail. Dans le cadre de la Charte internationale Espace et catastrophes majeures, ces modèles peuvent faciliter l’analyse rapide des images satellites après une catastrophe, en aidant à identifier les zones les plus touchées, mais aussi à ce qu’ils soient utilisés pour différents capteurs.
Un des défis majeurs de la détection automatique de changements, que j’ai pu rencontrer dans le cadre de la Charte, est que les modèles actuels fonctionnent de manière optimale sur des images satellites prises au nadir et sans nuages, conditions souvent non disponibles lors de catastrophes. Cette limitation peut compliquer l’analyse rapide et la prise de décisions urgentes. Pour surmonter ce problème et maximiser l’utilité des images satellites dans des conditions moins qu’idéales, j’ai entrepris l’entraînement d’un réseau de neurones spécifiquement conçu pour la détection de bâtiments dans ces situations dégradées. Bien que ces modèles puissent ne pas offrir la même précision que ceux entraînés sur des images parfaites, ils permettent néanmoins de fournir des indications précieuses pour les premières phases d’analyse post-catastrophe.
Personnellement, ce stage m’a permis d’approfondir mes connaissances en télédétection et en traitement de la donnée. Ma formation en astrophysique s’est révélée précieuse, notamment pour la manipulation d’images à haute résolution et la compréhension des phénomènes physiques. J’ai eu l’occasion de travailler dans un environnement stimulant, entouré d’experts de l’imagerie satellite et de l’intelligence artificielle. J’ai découvert le monde du deep learning, qui est à la fois passionnant en raison de ses capacités à obtenir des performances exceptionnelles pour des tâches complexes, mais qui reste une "boîte noire" rendant difficile l’interprétation de ses prédictions. Pour que mes travaux soient réutilisables, j’ai préparé des notebooks pour l’entraînement ou les tests d’application des méthodes de détection de changement, mis à disposition un pipeline complet sur GitHub pour l’utilisation de la librairie Pytorch lightning ainsi qu’une fiche de guide pour faire de la segmentation sémantique et fait une présentation de mes travaux à l’équipe EOLAB.
Cette expérience a confirmé l’importance d’une approche équilibrée, combinant avancées technologiques et expertise humaine pour des applications efficaces en situation de crise. Cette opportunité au sein du CNES et de l’équipe EOLAB, m’a non seulement permis d’élargir mes compétences techniques mais aussi d’apprécier l’importance d’une approche collaborative. Je suis convaincu que les compétences et les connaissances acquises durant ce stage seront précieuses pour mes futures expériences professionnelles, particulièrement dans le domaine en pleine expansion de l’analyse des données spatiales.
A - Géométrie d’acquisition des images satellites
Les images de télédétection sont obtenues numériquement sous forme de matrice de valeurs numériques, associant à chaque pixel une grandeur appelée radiométrie. Lorsque l’on obtient une image "en couleurs", c’est en réalité un ensemble de plusieurs matrices à différentes bandes spectrales (on parle d’image à plusieurs canaux). Les besoins de l’utilisateur font que pour certaines applications, il est important d’introduire la notion de "Qualité Image". On définit donc la qualité d’une image grâce à 3 domaines :
- La géométrie des images : bonne localisation, sans trop de déformation en haute et basse fréquence, précision altimétrique, bonne superposition multispectrale ou inter-bandes, etc.
- La radiométrie des images : bonne résolution radiométrique (capacité à distinguer deux cibles de luminosités très voisines), bonne restitution des couleurs, faible bruit radiométrique (capacité à avoir une image uniforme d’un paysage uniforme), précision d’étalonnage, gabarit spectral, etc
- La résolution des images : pas d’échantillonnage au sol, FTM (Fonction de Transfert de Modulation), repliement de spectres, etc.
La géométrie d’acquisition des capteurs influence fortement la résolution spatiale, l’angle de vision, l’altitude du satellite et le type d’orbite à utiliser :
- Capteur de type matriciel : Acquisition direct en 2 dimensions du paysage (film photographique, matrice de détecteurs), voir illustration à gauche de la Figure 23.
- Capteur de type push-broom : Acquisition successive de chaque ligne image par défilement du paysage dans le plan focal (barrette de détecteurs couvrant le champ latéral, identique au principe d’un scanner de photocopieuse), voir illustration au centre de la Figure 23.
- Capteur de type scanner : Acquisition successive de chaque pixel de chaque ligne par double balayage mécanique, le long des lignes puis le long des colonnes, voir illustration à droite de la Figure 23.
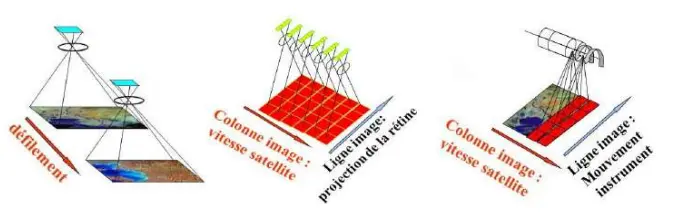
Figure 23 – Illustrations montrant les différentes géométries d’acquisitions des images optiques spatiales allant du capteur de type matriciel à gauche, du capteur de type push-broom au centre et du capteur de type scanner à droite. Crédits : CNES/ONERA/IGN
B - Les bases d’un réseau de neurones
Les neurones artificiels sont inspirés des neurones biologiques. Ils reçoivent une entrée, la transforment avec une fonction d’activation puis produisent une sortie. Les entrées sont pondérées et ces poids sont ajustés pendant l’apprentissage pour améliorer la performance du modèle (voir à gauche de la Figure 24). Un réseau de neurones artificiel est constitué de une à plusieurs couches de neurones. Les couches comprennent une couche d’entrée, une ou plusieurs couches cachées (définissant la "profondeur" du réseau), et une couche de sortie (voir à droite de la Figure 24). Chaque couche est connectée à la suivante par des poids et des biais, ajustés lors de l’entraînement.
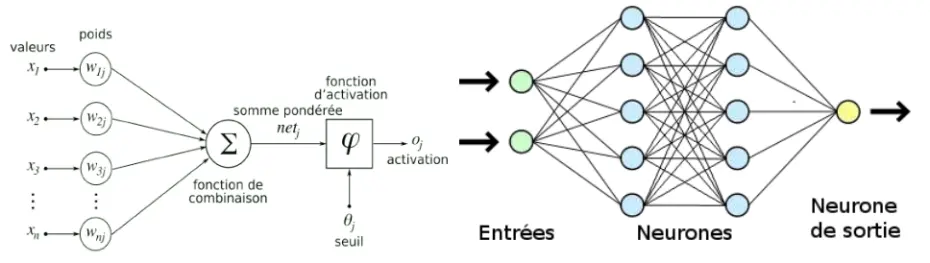
Figure 24 – Représentation mathématique/informatique d’un neurone artificiel à gauche et représentation simplifiée d’un réseau de neurones comprenant la couche d’entrée (en vert), les couches cachées (en bleu) et la couche de sortie (en jaune), à droite. Les valeurs (x1, ..., xn) représentent les entrées qui sont transformées par les poids synaptiques (w1j , ..., wnj ). Le neurone fait ensuite la somme pondérée de toutes ces entrées et la passe dans une fonction d’activation non linéaire φ avec un seuil θj qui ressort une sortie oj . Crédits : Semeurand, M., Sinat blog [11]
On parle de propagation avant, le processus où les entrées traversent les différentes couches du réseau jusqu’à la couche de sortie, produisant une prédiction. À chaque neurone, une fonction d’activation est appliquée pour introduire des non-linéarités et permettre au réseau de modéliser des relations complexes. La fonction de perte mesure ensuite l’erreur entre la prédiction du modèle et la valeur réelle. Les fonctions de perte courantes incluent l’erreur quadratique moyenne (MSE) pour les régressions et l’entropie croisée (Cross-Entropy Loss) pour les classifications. Ces différentes fonctions de perte sont essentielles pour diriger l’entraînement des modèles de deep learning en pénalisant les prédictions incorrectes.
La rétropropagation est le processus par lequel le réseau ajuste ses poids pour minimiser la
fonction de perte. L’erreur est propagée en arrière à travers le réseau, et les poids sont mis à
jour à l’aide de l’algorithme de descente de gradient ou d’autres techniques
d’optimisation.
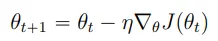
Avec θt qui représente les paramètres du modèle à l’itération t, η qui est le taux d’apprentissage, un hyperparamètre qui contrôle la taille des pas de mise à jour et ∇θJpθtq qui est le gradient de la fonction de perte Jpθq par rapport aux paramètres θ à l’itération t.
Bibliographie
- Badrinarayanan, V., Handa, A., Cipolla, R., et al. 2015, SegNet : A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling, arXiv:1505.07293 (https://arxiv.org/pdf/1505.07293)
- Caye Daudt, R., Le Saux, B., Boulch, A., et al. 2018, Détection dense de changements par réseaux de neurones siamois, hal-01823684 (https://hal.science/hal-01823684v1/file/2018_rfiap_changement.pdf)
- CNES, website of Centre National d’Etudes Spatiales (CNES - Centre national d'études spatiales)
- EOLAB group at CNES, presentation of the work team (Accueil - Lab'OT)
- Gupta, R., Goodman, B., Patel, N., et al. 2019, Creating xBD : A Dataset for Assessing Building Damage from Satellite Imagery, IEEE CVF (Creating xBD: A Dataset for Assessing Building Damage from Satellite Imagery)
- Hedhli, I., Moser, G., Zerubia, J., 2017, Nouvelle Méthode en Cascade pour la Classification Hiérarchique Multi-Temporelle ou Multi-Capteur d’Images Satellitaires Haute Résolution, HAL, hal-01632923 (Nouvelle Méthode en Cascade pour la Classification Hiérarchique Multi-Temporelle ou Multi-Capteur d'Images Satellitaires Haute Résolution - Archive ouverte HAL)
- International Disasters Charter : Kahramanmaras earthquakes in Türkiye (Kahramanmaras earthquakes in Türkiye - Activations de la Charte | Charte Internationale Espace et Catastrophes Majeures)
- International Disasters Charter website (Accueil | Charte Internationale Espace et Catastrophes Majeures)
- Pléiades satellites user documentation : Presentation of the mission (Pléiades - Earth Online)
- Pytorch lightning user documentation (Welcome to ⚡ PyTorch Lightning — PyTorch Lightning 2.5.0.post0 documentation)
- Semeurand, M., 2021, Présentation des réseaux de neurones artificiels, Sinat blog (Présentation des réseaux de neurones artificiels - SINAT BLOG)
- SpaceNet 4 Challenge : Off-Nadir Buildings (spacenet.ai/off-nadir-building-detection/)
- Weir, N., et al., 2019, The SpaceNet Challenge Off-Nadir Buildings: Introducing the winners (://spacenet.ai/off-nadir-building-detection/)
- Xview2 Challenge : Computer Vision for Building Damage Assessment using satellite imagery of natural disasters (xView2)